Named Entity Recognition (NER) is used to automatically identify key entities in text, especially people, organisations, and locations. In archival work, these are some of the most useful entry points for search, indexing, and access services.
The first dedicated-model benchmark in ArchXAI asked a practical question: which Hugging Face NER models are the strongest current candidates for multilingual archive indexing when labels are mapped to a shared PER / ORG / LOC scheme?
What we tested
This note focuses on dedicated transformer-based NER models. The benchmark covered multilingual, Estonian, Finnish, Latvian, and Russian model candidates that could realistically be integrated into AI-based cataloguing and indexing workflows.
The headline score is F1, which balances two practical errors: marking things that are not entities, and missing entities that should have been found. Higher is better.
Because the source models and datasets do not all use the same label inventory, the benchmark maps results to a shared PER / LOC / ORG scheme before scoring.
Headline results
| Language | Best dedicated model | Dataset | F1 (%) |
|---|---|---|---|
| 🇪🇪 Estonian | 51la5/roberta-large-NER |
et_modern |
75.7% |
| 🇫🇮 Finnish | Kansallisarkisto/finbert-ner |
fi_old |
75.2% |
| 🇱🇻 Latvian | 51la5/roberta-large-NER |
lv_diverse |
84.1% |
| 🪆 Russian | pierre-tassel/rapido-ner-entity |
ru_modern |
91.2% |
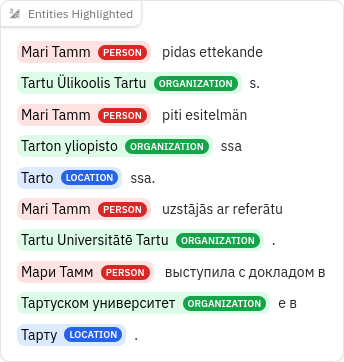
What the output looks like
Evaluation setup
Evaluation models
- 🌐 Multilingual
- 🇪🇪 Estonian
- 🇫🇮 Finnish
- 🇱🇻 Latvian
- 🪆 Russian
Evaluation datasets
- 🌐 Multilingual
et_multileg.conll(100 804)fi_multileg.conll(96 488)lv_multileg.conll(110 860)
- 🇪🇪 Estonian
et_modern.conll(165 947)et_old.conll(54 069)
- 🇫🇮 Finnish
fi_old.conll(51 839)
- 🇱🇻 Latvian
lv_modern.conll(21 951)lv_diverse.conll(199 155)
- 🪆 Russian
ru_modern.conll(47 187)ru_oldish.conll(18 838)
Early interpretation
The main engineering conclusion is still straightforward: dedicated NER models are the default choice for large-scale indexing. They are fast enough for bulk processing, and the best-performing model can be selected by language and collection type.
The language-level results also show that a single multilingual baseline is not always the only answer. In Estonian and Latvian, 51la5/roberta-large-NER performed especially well, while Finnish favored Kansallisarkisto/finbert-ner, and Russian favored pierre-tassel/rapido-ner-entity.
Operationally, transformer NER still has the clearest advantage for routine archive processing: in local runs, these models process text in milliseconds per sentence, while LLM-based extraction takes seconds per sentence and is therefore better suited to targeted enrichment or fallback use.
What to update next
The next useful update is to add more dataset-specific detail below the language summary, especially for legal and historical material where the archive use case is hardest. The strongest dedicated models should then be fine-tuned on project-specific archival data to test how much additional recall and robustness can be gained.